Motivation
Unicode allows two different encodings for diacritics. This apparently creates some issues in practice.
WARNING!
Update 2021-10-21: I learned that this blog post is just wrong. It uses the assumption that Esperanto uses the caron diacritic. However, it actually uses the breve diacritic. I did not recognize this because Neo2 breve diacritic is broken and duolingo renders both diacritics the same.
I am sorry to get this analysis wrong in the first place. This blog post is only here for archival purposes.
The source of the problem
There are two ways to encode the character ǔ. I will analyze them in a python session.
>>> u1 = 'ǔ'
>>> len(u1)
1
>>> ord(u1)
468
>>> hex(ord(u1))
'0x1d4'
>>> u1.encode('utf-8')
b'\xc7\x94'
>>> u1.encode('utf-16')
b'\xff\xfe\xd4\x01'
>>> u2 = 'ǔ'
>>> len(u2)
1
>>> ord(u2)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: ord() expected a character, but string of length 2 found
>>> u2.encode('utf-8')
b'u\xcc\x8c'
>>> u2.encode('utf-16')
b'\xff\xfeu\x00\x0c\x03'
>>> import unicodedata
>>> [unicodedata.normalize(std, 'ǔ') for std in ['NFC', 'NFKC', 'NFD', 'NFKD']]
['ǔ', 'ǔ', 'ǔ', 'ǔ']
>>> [len(unicodedata.normalize(std, 'ǔ')) for std in ['NFC', 'NFKC', 'NFD', 'NFKD']]
[1, 1, 2, 2]-
On the one hand, there is the “COMBINING CARON” (U+030C) that can be combined with “LATIN SMALL LETTER U” (U+0075). In UTF-8, this is encoded as [0xC7 0x94].
-
On the other hand, there is the “LATIN SMALL LETTER U WITH CARON” (U+01D4). In UTF-8, this is encoded a [0xCC 0x8C].
Learning platforms
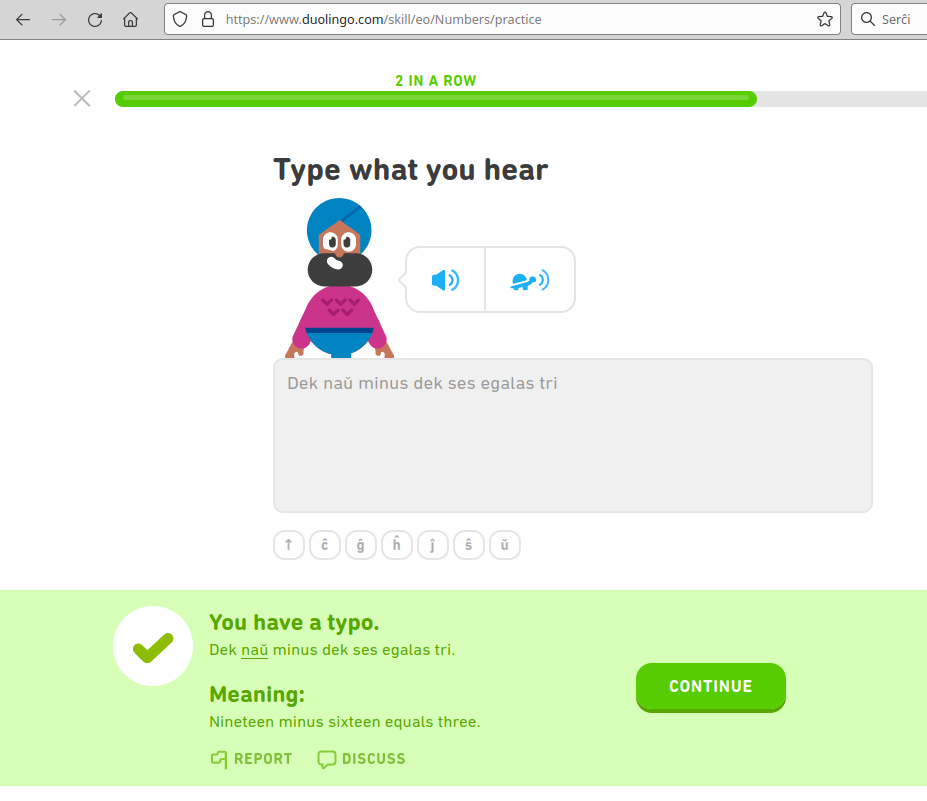
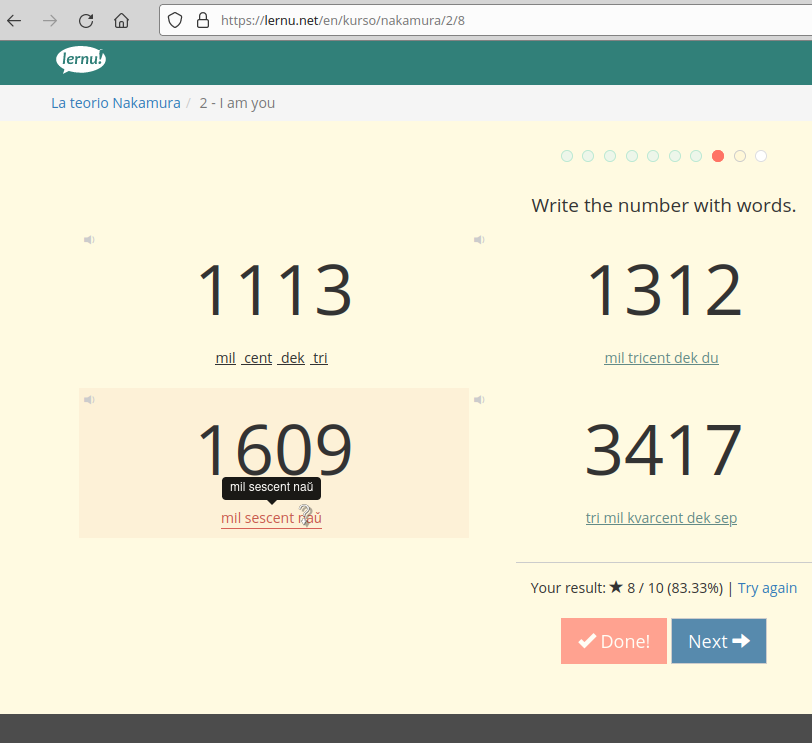
Learning platforms evaluate the correctness of students' responses. In the case of duolingo and lernu, this is done via string comparison without respect for the two possible encodings:
duolingo
lernu
Conclusion
I wanted to present this as an issue with Unicode in practice. To solve the problem, you can apply some Unicode normalization algorithm before comparing strings.
I filed a bug report on duolingo.